Plant.id API Incidents
You can find the reports from the past Plant.id API Incidents bellow
You can check whether the Plant.id API is running at the following page: http://status.plant.id/.
2023-05-21 slow identification for 0.05% of traffic
2023-05-26 10:01 [investigating] On of our GPU workers sometimes mysteriously freezes a causes a tiny amount of traffic to be inefficiently requeued causing some requests to take much slower than we are used to (sometimes even a minute or two).
Note: The new efficient requeueing system is already developed and we are planning to release it during the summer.
2022-07-07 API outage
2022-07-07 11:18 [update] We switched back to the boosted database and turned on additional notifications to prevent this issue in the future.
2022-07-07 11:04 [resolved] We switched to the recovery database. Plant.id is working again.
2022-07-07 10:20 [update] We are increasing the database space and creating a new recovery database.
2022-07-07 10:01 [investigating] Our database ran out of storage space and switched to the read-only mode. Identification stopped working.
2021-08-19 API outage
2021-08-19 6:09 [resolved] The migration took almost 2 hours.
2021-08-19 4:10 [investigating] Our database node stopped responding. The traffic could not be automatically routed to a dedicated secondary node for reasons we are still investigating. Our Engineering team immediately contacted the cloud provider. We decided to migrate DB to another cluster.
2020-12-31 API is unable to process new identifications
2020-12-31 17:25 [resolved] Problem with the database has been solved and the API is fully operational. The outage took 96 minutes.
2020-12-31 15:00 [investigating] We are experiencing the unexpected database issue resulting to read only transactions. Because of that the API is unavailable to process new identifications.
2020-11-10 Semi-regular performance degradation
2020-11-10 11:53 [analysis] The database provider is still analyzing the issue. We have prepared steps for database migration.
2020-11-08 10:25-10:44 [investigating] Performance degradation.
2020-11-08 3:00-3:15 [investigating] Performance degradation.
2020-11-09 6:47-7:18 [investigating] Performance degradation.
2020-11-03 16:38 [update] After a few days the issue has been communicated to the database provider and passed along their sysadmins, the performance issues stopped for a while.
2020-10-29 14:05 [investigating] The incident described below (on 2020-10-15) repeated a few times during the last two weeks with a different duration and intensity. We have investigated the cause.
Our database provider experiences short (usually few minutes) semi-regular performance degradations. Plant.id performance is significantly impacted by these degradations by slower response (see the graph how long it takes for our server to respond in average during the degradation timeframe) and rare outages. We are strongly pushing the provider for resolving the issue. In the same time, we are in the process of researching a more stable distributed database solution.
The issue is not severe, but we aim to have this issue resolved within the first half of November.
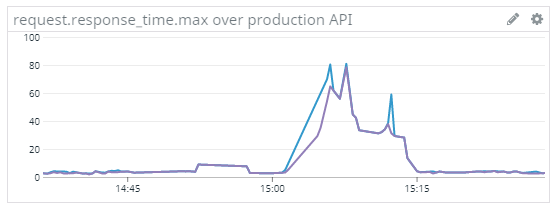
2020-10-15 Performance degradation
2020-10-15 11:40 [analysis] If these incidents occur more often the engineering team will utilise the load balancer to replicate the service function across different data centers to mitigate connectivity issues.
2020-10-14 18:40 [resolved] There was a short network connection degradation to one of our virtual servers. The result was a slight performance degradation of identification service. For a short brief of time, some identification requests took more than a minute to resolve.
2020-07-24 Short outage during database upgrade
2020-07-24 12:20 [analysis] Our Engineering team is in contact with the database service provider discussing possible precautions to mitigate the issue in the future.
2020-07-24 12:15 [resolved] The database subsystem was not available shortly after its upgrade to a more powerful tier. Since the upgrade was performed in low-traffic hours, just a few requests were affected. Also, the outage was correctly displayed on status.plant.id.
2020-07-24 11:57 [investigating] Outage.
2020-05-27 Identification function has been affected by a software error
2020-05-27 13:20 [analysis] Our Engineering team is discussing some steps to mitigate the issue in the future. It will probably be a canary deployment for Plant.id web.
2020-05-27 12:09 [resolved] The root of the issues was an error in the codebase which has not been caught by our integration tests (this one is kind of hard to detect automatically). The issue has been already fixed as one of our website users notified us about unusual results.
2020-05-26 09:55 [investigating] The identification is not working correctly in 10% of cases (for images specific dimension range).
2020-05-25 Service availability has been impacted by a low disc space
2020-05-25 13:00 [analysis] Since the unexpected nature of the issue, the incident was not correctly displayed on the status page. Only low-priority alert has been triggered. That’s why the issue was not fixed immediately, but it took the whole night for us to register the issue.
2020-05-25 06:31 [resolved] The disc space of the permanent cache ran out due to high traffic in recent weeks. Our Engineering team has set up the appropriate high-priority alert and also adjusted the rules for storing the data to the cache.
2020-05-25 01:46 [investigating] API is not available.
2020-04-20 Networking issue impacting service performance
2020-04-20 17:08 [analysis] The API experienced lower performance for 4 hours between 12:01 and 16:01. In this time frame no significant amount of identification requests failed. The average time for identification temporarily grew from 2 to 400 seconds. The incident was correctly displayed on the status page. Our Engineering team will discuss the steps to mitigate these issues in the future.
2020-04-20 16:01 [resolved] The service provider resolved the networking issues and fixed the mentioned performance issues.
2020-04-20 12:54 [update] Our Engineering team continues to monitor the Issue. The primary cause is probably a networking issue on the side of our main server provider. We will post an update as soon as the issue is fully resolved.
2020-04-20 12:01 [investigating] Our Engineering team is investigating an issue with networking which is impacting Plant.id performance. During this time, you may experience slow response from services. We apologize for the inconvenience and will share an update once we have more information.